今回のゴールと「RAG」とは
第2回・第3回で作ったボットは、AIが元から持っている“一般的な知識”で答えていました。だから「自社の就業規則では?」のような社内固有の質問には答えられません。それを解決するのが、今回作るナレッジ(RAG)です。
RAGは Retrieval-Augmented Generation(検索拡張生成) の略で、むずかしく聞こえますが、やることはシンプルです。「AIに自社の資料を渡しておき、質問が来たら関連する部分を“検索”して、それを参考に答えてもらう」仕組みです。たとえるなら、AIに“カンニングペーパー(社内資料)”を持たせてあげるイメージです。
💡 今回のゴール
- 社内資料を読み込ませるナレッジ(知識ベース)を1つ作る
- チャンク(資料の分け方)とインデックス方法(探し方)の違いを理解する
- クレジットを消費しない設定(Economical)でナレッジを完成させる
※今回はナレッジの“土台作り”まで。これをボットにつないで完成させるのは第5回です。
はじめに:アップロードする資料の注意点
⚠️ いきなり“本物の社外秘”を上げないでください
ナレッジに登録した資料は、Dify Cloud(海外のクラウドサービス)に保存されます。練習の段階では、個人情報や社外秘を含む本物の資料は使わないでください。まずは差し支えのない資料や、ダミーのサンプルで試し、本番運用の前に必ず自社の情報取り扱いルールを確認しましょう。本記事でも、実在しない架空のサンプル「社内FAQ・オフィス利用ガイド」を使います。
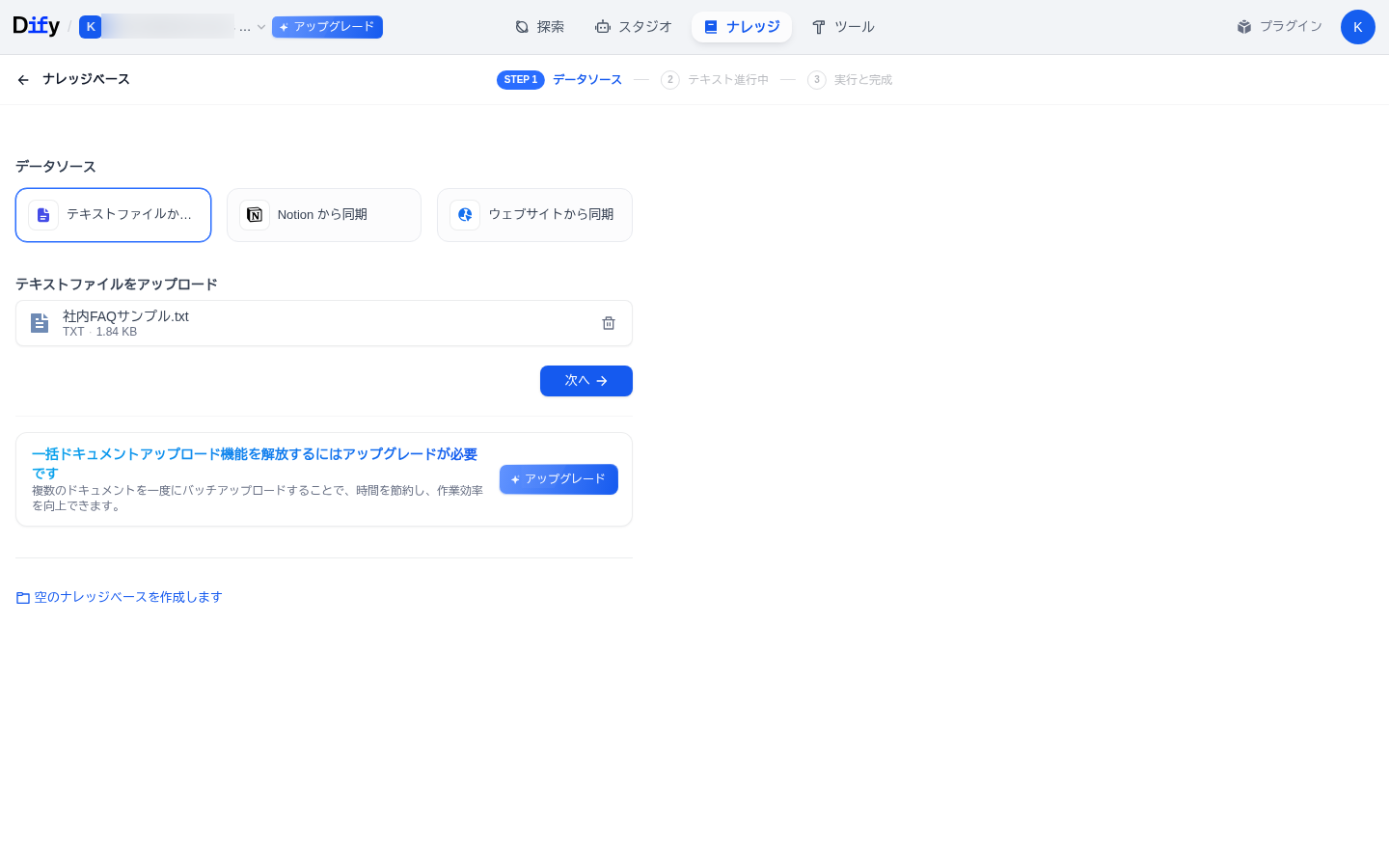
① ナレッジを作って資料をアップロードする
上部メニューの ナレッジ を開き、ナレッジベースを作成 をクリックします。続いて テキストファイルからインポート が選ばれた状態で、資料ファイルをドラッグ&ドロップ(または「参照」から選択)します。
対応ファイルは幅広く、PDF・Word(DOC/DOCX)・Excel(XLS/XLSX)・PowerPoint・テキスト・Markdown・HTML・CSV などが使えます。今回は架空のサンプルFAQ(テキストファイル)をアップロードしました。
📄 同じサンプルをダウンロードして試せます
この記事で使った架空の「社内FAQ・オフィス利用ガイド(サンプル)」テキストです。ダウンロードして、同じ手順をそのまま試せます(実在の社内規程ではありません)。
⚠️ Sandboxプランの上限(容量に注意)
無料のSandboxでは、1ファイル15MBまで・一度にアップロードできるのは1ファイル(複数まとめてのアップロードは有料機能)。ナレッジ全体ではドキュメント50件・合計50MBまでです。大きなPDFは、章ごとに分割するなどして1ファイル15MB以内に収めましょう。
② チャンク設定とインデックス方法を選ぶ
次へ を押すと、2つの設定が出てきます。少し専門的ですが、初心者向けに要点だけ押さえれば大丈夫です。
チャンク設定(資料の“分け方”)
チャンクとは、長い資料を検索しやすい小さなかたまりに分割することです。AIは資料を丸ごと読むのではなく、質問に関連するチャンクだけを探して使います。分け方は2モードあります。
- 汎用(General)… いちばん標準的な分け方。まずはこれでOKです。
- 親子(Parent-child)… 検索用の小さなかたまりと、文脈用の大きなかたまりを使い分ける発展的なモード。
チャンクをプレビュー を押すと、資料が実際にどう分割されるかを右側で確認できます(サンプルFAQが項目ごとのチャンクに分かれているのが分かります)。
インデックス方法(資料の“探し方”)― ここがクレジットの分かれ道
もうひとつが インデックス方法。これはクレジット消費に直結する重要な選択です。
| 方法 | 仕組み | クレジット |
|---|---|---|
| 経済的 (Economical) | キーワードで探す方式(転置インデックス)。手軽。 | 消費ゼロ ✓本連載の既定 |
| 高品質 (High-Quality) | 意味で探す方式(ベクトル/埋め込み)。精度が高い。 | 埋め込みでクレジットを消費 |
本連載では、まずクレジットを使わない「経済的」を選びます。図4-2のように「経済的」を選択してください(選ぶと青い枠が付きます)。
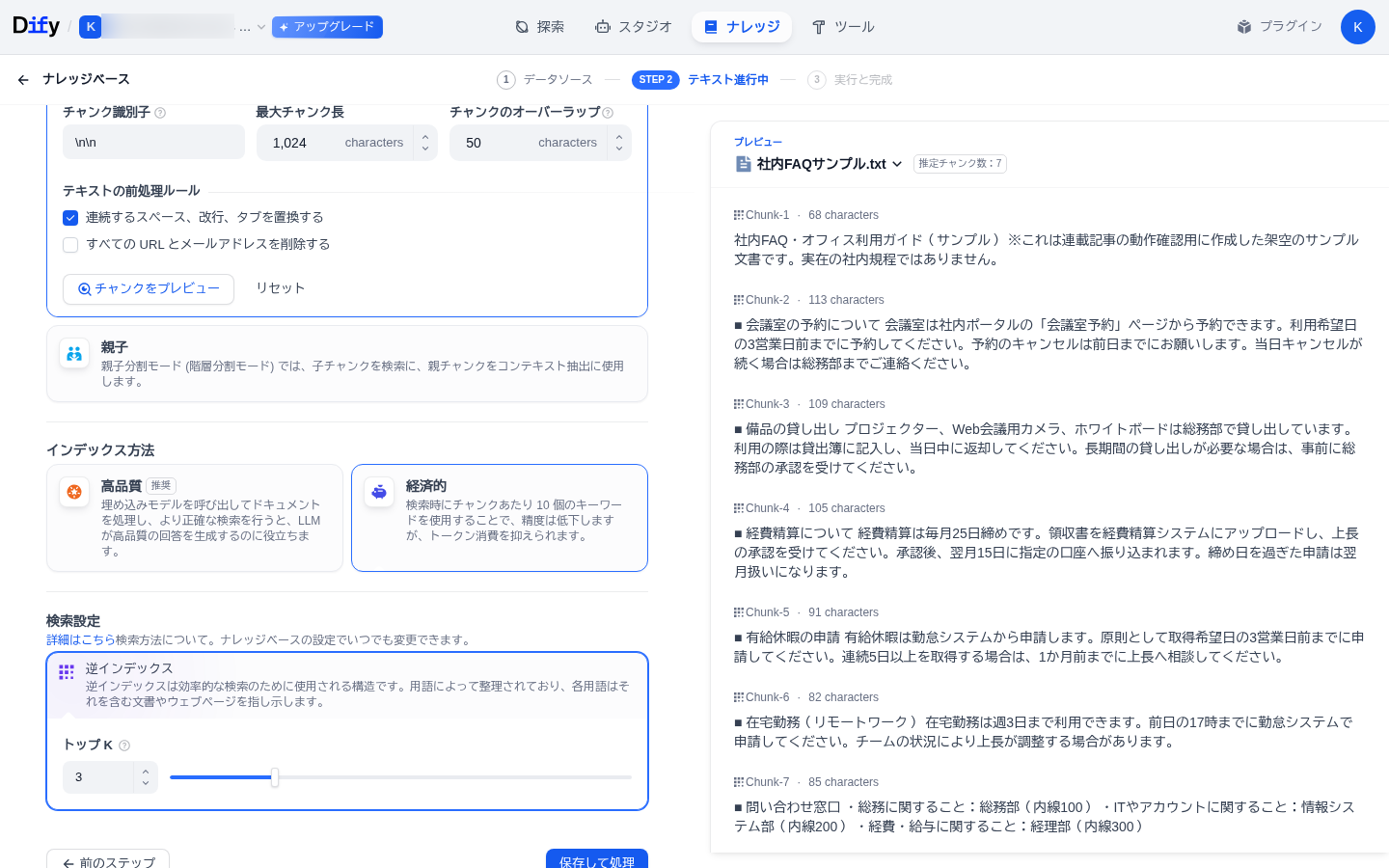
⚠️ 「高品質」は“あと戻りできない”&クレジット消費
高品質(ベクトル検索)は精度が上がりますが、埋め込みモデルを使うためクレジットを消費します。さらにDifyの仕様上、一度「高品質」で処理すると「経済的」には戻せません(画面にも「経済的モードに戻すことはできません」と表示されます)。精度を上げたいときの選択肢として、第5回であらためて扱います。まずは無料の「経済的」で十分です。
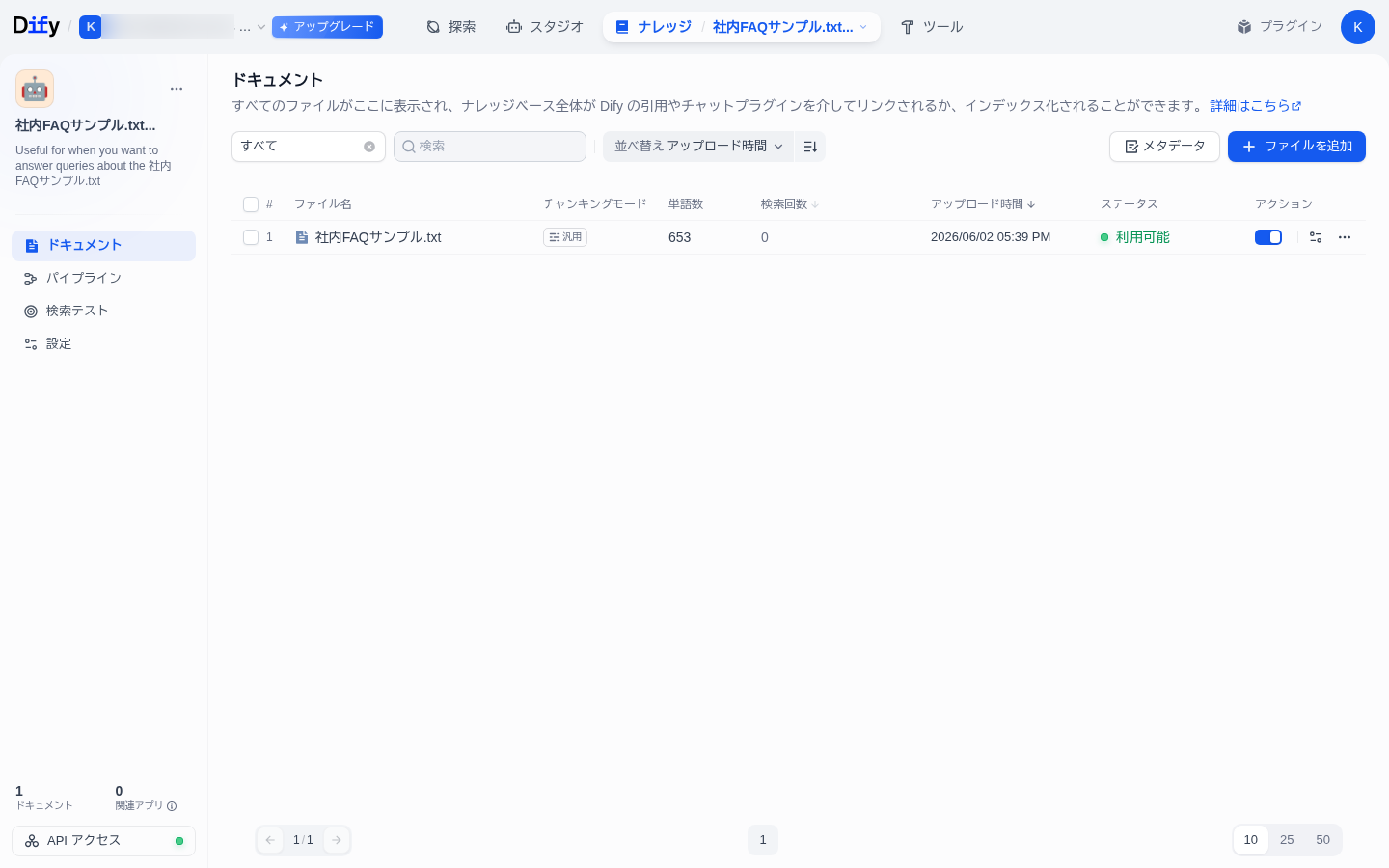
③ 保存して処理 ― ナレッジ完成
設定できたら 保存して処理 をクリックします。経済的モードなら処理はすぐ終わり、ドキュメントのステータスが「利用可能」になればナレッジの完成です。チャンキングモードが「汎用」、単語数なども表示されます。
④ クレジットの確認
恒例のクレジット確認です。設定▸モデルプロバイダー▸クォータ を見てみましょう。「経済的」で作ったナレッジは、AI(埋め込みモデル)を使わないため、クレジットは消費されません(残量は変わらないはずです)。資料を読み込ませる土台を、コストゼロで用意できました。
💰 ナレッジとクレジットの関係
- 経済的(キーワード検索):作成・検索ともにクレジット消費なし
- 高品質(ベクトル検索):資料を読み込む際の埋め込みでクレジットを消費(戻せない)
まとめと次回予告
今回は、社内資料(架空のサンプルFAQ)を読み込ませてナレッジ(RAG)を作りました。チャンクとインデックス方法の意味を理解し、クレジットを使わない「経済的」で完成まで到達しました。ただし、これはまだ“資料の検索エンジン”ができただけ。ボットとはつながっていません。
いよいよ連載の目玉です。今回のナレッジを第2回のチャットボットに接続し、出典付きで自社資料から答える“社内FAQアシスタント”を完成させます。検索の精度を上げる設定(高品質へのアップグレード判断)にも触れます。
この記事で参照した公式情報
- Dify Docs — Create Knowledge(ナレッジの作成)
- Dify Docs — Chunking(チャンク設定)
- Dify Docs — Indexing Methods(Economical / High-Quality)
- Dify — Pricing(ナレッジの上限:50文書/50MB等)
※ 画面のメニュー名や対応ファイル形式・上限は、Difyのアップデートで変わることがあります。本記事は公開時点の情報・実画面にもとづいています。アップロードした文書は架空のサンプルです。スクリーンショット内のワークスペース名(メールアドレス)は記事用に伏せています。